更新时间:2021-03-11 来源:黑马程序员 浏览量:

随着Hadoop的不断发展,Hadoop生态体系越来越完善,现如今已经发展成一个庞大的生态体系,如图1所示。
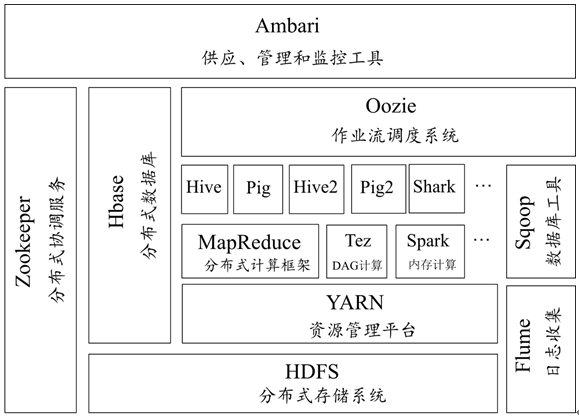
图1 Hadoop生态圈
从图1中可以看出,Hadoop生态体系包含了很多子系统,下面介绍一些常见的子系统,具体如下:
1. HDFS分布式文件系统
HDFS是Hadoop分布式文件系统,它是Hadoop生态系统中的核心项目之一,是分布式计算中数据存储管理基础。HDFS具有高容错性的数据备份机制,它能检测和应对硬件故障,并在低成本的通用硬件上运行。另外,HDFS具备流式的数据访问特点,提供高吞吐量应用程序数据访问功能,适合带有大型数据集的应用程序。
2. MapReduce分布式计算框架
MapReduce是一种计算模型,用于大规模数据集(大于1TB)的并行运算。“Map”对数据集上的独立元素进行指定的操作,生成键值对形式中间结果;“Reduce”则对中间结果中相同“键”的所有“值”进行规约,以得到最终结果。MapReduce这种“分而治之”的思想,极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。
3. Yarn资源管理框架
Yarn(Yet Another Resource Negotiator)是Hadoop 2.0中的资源管理器,它可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
4. Sqoop数据迁移工具
Sqoop是一款开源的数据导入导出工具,主要用于在Hadoop与传统的数据库间进行数据的转换,它可以将一个关系型数据库(例如,MySQL、Oracle等)中的数据导入到Hadoop的HDFS中,也可以将HDFS的数据导出到关系型数据库中,使数据迁移变得非常方便。
5. Mahout数据挖掘算法库
Mahout是Apache旗下的一个开源项目,它提供了一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。Mahout包含许多实现,包括聚类、分类、推荐过滤、频繁子项挖掘。此外,通过使用 Apache Hadoop 库,Mahout 可以有效地扩展到云中。
6. Hbase分布式存储系统
HBase是Google Bigtable克隆版,它是一个针对结构化数据的可伸缩、高可靠、高性能、分布式和面向列的动态模式数据库。和传统关系数据库不同,HBase采用了BigTable的数据模型:增强的稀疏排序映射表(Key/Value),其中,键由行关键字、列关键字和时间戳构成。HBase提供了对大规模数据的随机、实时读写访问,同时,HBase中保存的数据可以使用MapReduce来处理,它将数据存储和并行计算完美地结合在一起。
7. Zookeeper分布式协作服务
Zookeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和HBase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等用于构建分布式应用,减少分布式应用程序所承担的协调任务。
8. Hive基于Hadoop的数据仓库
Hive是基于Hadoop的一个分布式数据仓库工具,可以将结构化的数据文件映射为一张数据库表,将SQL语句转换为MapReduce任务进行运行。其优点是操作简单,降低学习成本,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
9. Flume日志收集工具
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
猜你喜欢:
1024首播|39岁程序员逆袭记:不被年龄定义,AI浪潮里再迎春天
2025-10-241024程序员节丨10年同行,致敬用代码改变世界的你
2025-10-24【AI设计】北京143期毕业仅36天,全员拿下高薪offer!黑马AI设计连续6期100%高薪就业
2025-09-19【跨境电商运营】深圳跨境电商运营毕业22个工作日,就业率91%+,最高薪资达13500元
2025-09-19【AI运维】郑州运维1期就业班,毕业14个工作日,班级93%同学已拿到Offer, 一线均薪资 1W+
2025-09-19【AI鸿蒙开发】上海校区AI鸿蒙开发4期5期,距离毕业21天,就业率91%,平均薪资14046元
2025-09-19















 AI智能应用开发
AI智能应用开发 AI大模型开发
AI大模型开发 AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+
AI嵌入式+ AI大数据开发
AI大数据开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作运营
AI视频创作运营

















.jpg)