



Zookeeper集群的配置一共分为5步,首先要修改Zookeeper的配置文件,进入Zookeeper解压目录下的conf目录,复制配置文件zoo_sample.cfg并重命名为zoo.cfg,具体命令如下:查看全文>>

Spark可以通过并行集合创建RDD。即从一个已经存在的集合、数组上,通过SparkContext对象调用parallelize()方法创建RDD。查看全文>>
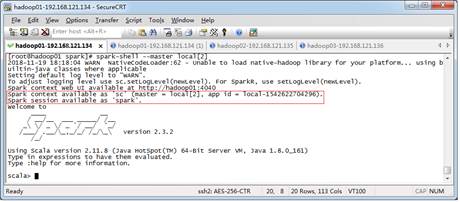
创建SparkSession对象可以通过“SparkSession.builder().getOrCreate()”方法获取,但当我们使用Spark-Shell编写程序时,Spark-Shell客户端会默认提供了一个名为“sc”的SparkContext对象和一个名为“spark”的SparkSession对象,因此我们可以直接使用这两个对象查看全文>>

DataFrame是一种以RDD为基础的分布式数据集,因此DataFrame可以完成RDD的绝大多数功能,在开发使用时,也可以调用方法将RDD和DataFrame进行相互转换。查看全文>>
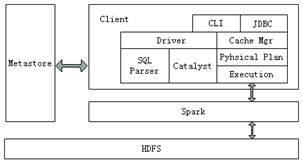
Spark作为开源项目,外部开发人员可以针对项目需求自行扩展Catalyst优化器的功能。要想很好地支持SQL,就需要完成解析(Parser)、优化(Optimizer)、执行(Execution)三大过程。Catalyst优化器在执行计划生成和优化的工作时候,它离不开自己内部的五大组件,具体介绍如下所示。查看全文>>














 AI智能应用开发
AI智能应用开发 AI大模型开发
AI大模型开发 AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+
AI嵌入式+ AI大数据开发
AI大数据开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作运营
AI视频创作运营














.jpg)